
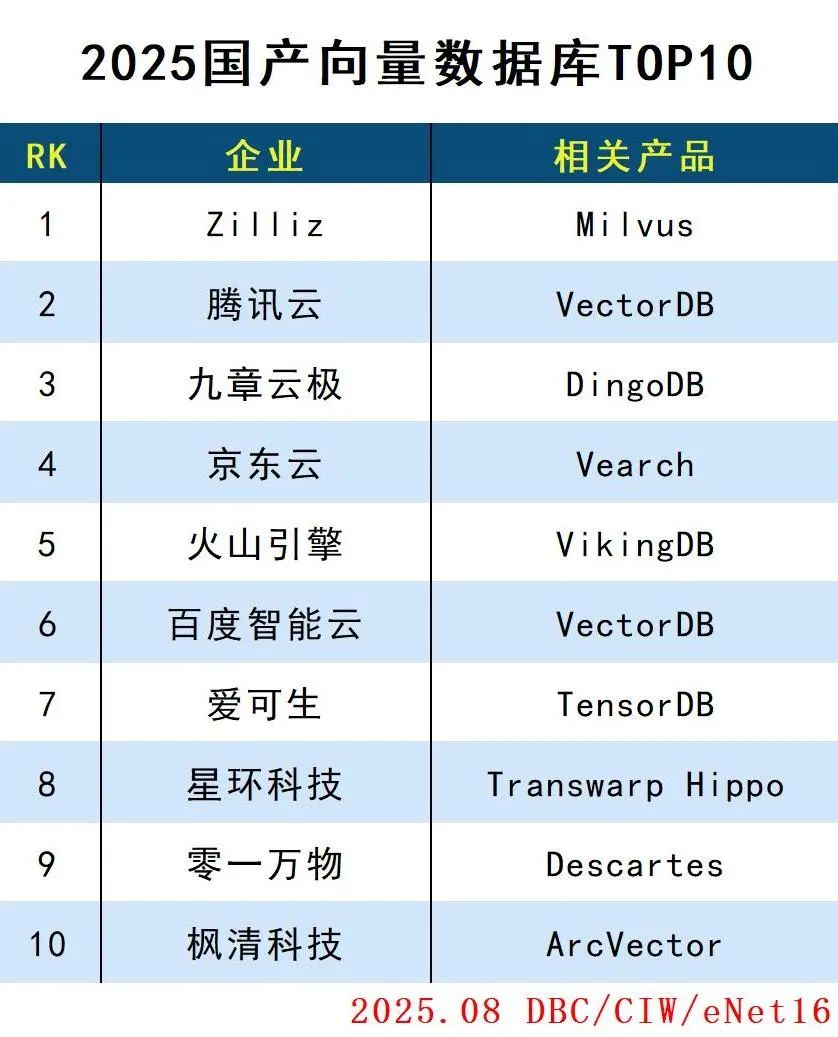
2025国产向量数据库TOP10
详情
外部记忆体
随着近年来大模型产业的蓬勃发展,一个曾经局限于特定领域的技术赛道——向量数据库,正逐渐成为业界关注的焦点。这一转变源于大模型技术演进对数据存储和处理能力提出的新需求。
大模型的核心优势在于其强大的复杂计算能力,包括语义理解和内容生成等任务。然而,这些模型的参数量通常高达数十亿甚至数千亿,无法直接存储实时或海量的非结构化数据。与此同时,传统的关系型数据库虽然擅长处理结构化数据(如表格、行列等),但其依赖的关键词匹配和规则引擎在处理高维向量数据(如文本、图像、音频的嵌入表示)时面临显著挑战,主要表现为语义理解不足、检索效率低下等瓶颈问题。
在此背景下,向量数据库应运而生,通过采用优化的索引结构(如HNSW、IVF)和先进的相似性搜索算法(如余弦距离、欧式距离),实现了对海量非结构化数据的毫秒级检索。这一技术突破不仅解决了传统数据库难以支持的模糊语义匹配问题,更通过其高效的数据存储与检索能力,成为大模型不可或缺的“外部记忆体”,为大模型提供了强大的数据支持。
从市场规模来看,向量数据库正处于高速增长阶段。根据权威市场研究机构的数据,该市场规模近年来呈现指数级增长态势,预计到2025年将达到30.4亿美元,复合年增长率(CAGR)为23.7%。其中,中国市场占据全球约12.74%的份额。值得注意的是,中国AI产业已占据全球15%的市场份额,相比之下,向量数据库在中国市场仍具有显著的增长潜力和发展空间。
AI核心引擎
近年来,向量数据库市场经历了显著的技术演进和生态扩展,其发展态势主要体现在以下三个关键维度:
首先,数据规模呈现指数级跃升。五六年前,数千万至亿级的向量数据规模已是“超大规模”,而如今,百亿级乃至千亿级向量数据的处理能力已成为头部厂商标配。据Gartner预测,2025年全球数据总量将达到约175 ZB(1ZB=10^21字节),其中非结构化数据约占所有新增信息的80%至90%,这直接倒逼向量数据库在存储效率、计算密度和分布式架构上持续突破。
其次,应用场景实现多元化突破。向量数据库已从最初的大模型知识库检索,逐步延伸至AI全生命周期管理。在模型训练阶段,它被用于数据清洗和特征提取;在应用层面,其价值在多模态数据处理、智能推荐系统、风险控制与欺诈检测等领域得到充分体现。特别是在生物医药领域,向量数据库正革新传统研发范式,通过将蛋白质结构和基因序列转化为特征向量,为药物筛选和新药研发提供精准高效的解决方案。这种跨领域的应用扩展,彰显了向量数据库作为AI基础设施的战略价值。
最后,成本优化日渐成为用户关注焦点。随着数据规模和应用场景的爆发式增长,如何降低向量数据库的使用成本已成为业界亟须解决的问题。这既包括硬件层面的存储成本优化,也涉及软件层面的计算效率提升。具体而言,用户越来越关注如何通过算法优化减少计算资源消耗、如何实现冷热数据的分级存储,以及如何通过分布式架构提升资源利用率。这种对成本效益的追求,正在推动向量数据库技术向更高效、更经济的方向演进。
这些发展趋势表明,向量数据库正从单一的技术工具演变为支撑AI产业发展的关键基础设施,其市场价值和技术影响力将持续提升。未来,随着技术的进一步成熟和生态的完善,向量数据库将在更多领域发挥其独特优势,推动产业数字化转型和智能化升级。
结语
当前,向量数据库正从技术选型转向战略必争,其发展不仅关乎数据处理效率,更是AI时代数据主权与算力话语权的核心战场。谁能掌握高维数据处理的底层算法、构建跨模态融合的生态闭环,并在成本控制上实现规模化突破,谁将主导这场非结构化数据爆发的下半场。
这场围绕AI时代新基建的竞赛,将深刻影响千行百业的智能化进程与高度。
来源:德本咨询
-
 详细内容请点击查阅...上传时间:2026-01-22 14:57:43.0
详细内容请点击查阅...上传时间:2026-01-22 14:57:43.0 -
详细内容请点击查阅...上传时间:2026-01-21 11:06:03.0
-
详细内容请点击查阅...上传时间:2026-01-09 10:10:35.0
-
详细内容请点击查阅...上传时间:2026-01-09 10:09:20.0
-
详细内容请点击查阅...上传时间:2026-01-09 10:04:42.0
-
详细内容请点击查阅...上传时间:2026-01-09 10:03:06.0
 联系客服
联系客服

